-
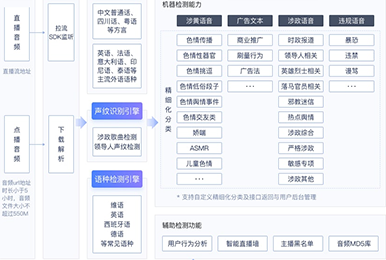
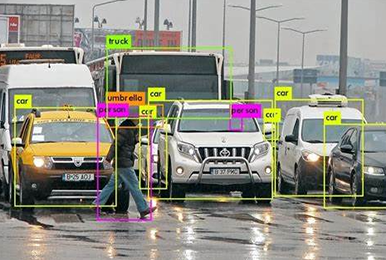
政府及公共事业如:安防监控
大型语言模型在政府和公共安防监控领域具有广泛的应用前景,从自动解析紧急通讯、实时社交媒体监控,到与计算机视觉算法相结合的视频内容分析,以及数据分析和预测潜在的公共安全问题。这些模型还可以用于自动生成各种安全报告和警报,进一步提升应急响应的速度和准确性。但随之而来的是一系列挑战和伦理考虑,包括但不限于数据隐私、模型准确性、潜在的算法偏见以及可解释性等问题。特别是在处理涉及个人隐私和敏感信息的任务时,如何遵守数据保护和隐私法规是一大关注点。此外,由于公共安全具有极高的重要性和敏感性,模型的误报和漏报都可能带来严重的后果,因此,需要有严格的评估和审计机制来确保模型的准确性和可靠性。在应用这些先进技术的同时,政府需要与科技提供商、监管机构和公众等多方合作,以制定全面的策略和规范,确保技术应用不仅能有效提高公共安全,而且也能符合伦理和法律规定,获得社会广泛的接受和信任
-
城市智能体
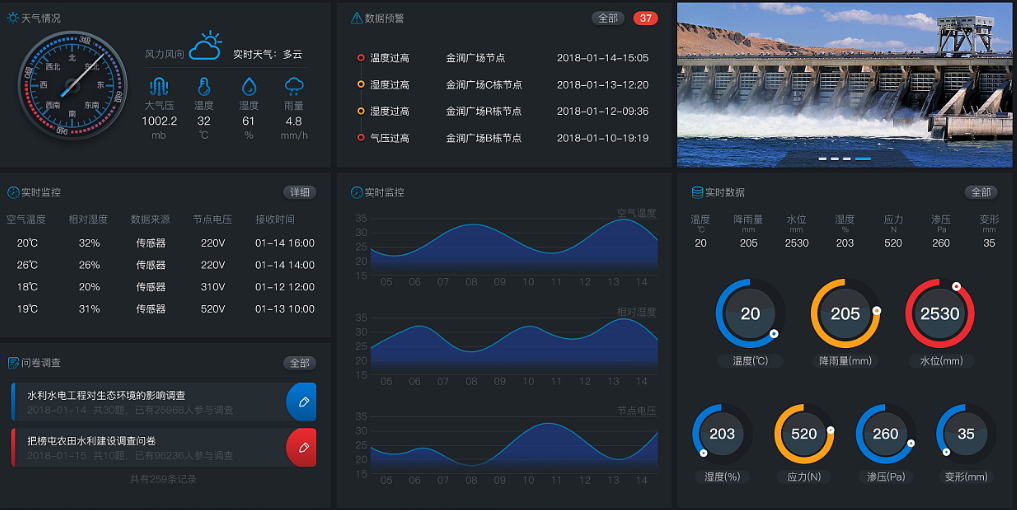
大型语言模型在城市智能体系统中拥有广阔的应用前景,包括但不限于交通管理、环境监测、公共服务自动化、应急响应以及社会舆情分析。这些模型能够处理大量的数据并生成有针对性的策略或预警,从而极大地提高城市管理的效率和准确性。然而,这也带来了一系列复杂的挑战,包括数据隐私和安全、模型准确性和偏见、人机交互的可接受性,以及需要遵循的法律和伦理规定。因此,当政府和相关组织考虑将大型语言模型融入到城市智能体系统中时,必须进行全面和细致的规划,以确保技术应用不仅高效而且责任明确。这包括与多个利益相关方,如科技提供商、监管机构和居民等,进行广泛的合作和咨询,旨在创建一个既符合技术潜力也符合社会伦理和法律标准的综合性解决方案。
-
媒体文娱
大型语言模型在媒体和文娱产业中的应用既广泛又具有革命性,涵盖内容生成、用户互动、数据分析、自动翻译以及虚拟角色设计等多个方面。这些模型有助于加速和优化内容创作,增强用户参与度,提供更深入的市场洞见,并促进全球化和多语言交流。然而,这些应用也面临一系列挑战和伦理考量,包括内容的真实性和准确性,版权和创作归属,以及用户数据和隐私保护。在面对如此多样和复杂的应用场景时,企业和组织需要细致地规划和实施,以确保符合法律规定和社会伦理标准。这可能涉及与多个利益相关方,如内容创作者、用户、监管机构和技术提供商,进行广泛的沟通和合作。总体而言,大型语言模型为媒体和文娱产业提供了巨大的机会和潜力,但要实现这一潜力,就需要在应用实践中找到平衡点,确保技术进步与伦理责任、法律规定和文化敏感性等多个方面都能得到妥善考虑和处理。
-
汽车
大型语言模型在汽车产业中展示出广泛的应用前景,从智能助手和车载系统的人机交互,到质量控制、客户服务和市场研究等多个领域都有其价值。这些模型能够提供更自然和直观的操作界面,分析和优化制造过程,以及提供针对性的市场洞见和客户服务。然而,应用这些先进技术也面临一系列挑战,包括数据安全和隐私保护、系统的准确性和可靠性,以及复杂的法律和道德责任问题。特别是在涉及到高风险应用如自动驾驶时,这些考量变得尤为重要。因此,企业和研究机构需要在推动技术创新的同时,也务必考虑到这些伦理和安全因素,以确保模型应用不仅高效而且责任明确。这可能涉及与多个利益相关方,包括消费者、监管机构和供应商,进行全面而细致的合作和规划。
-
金融
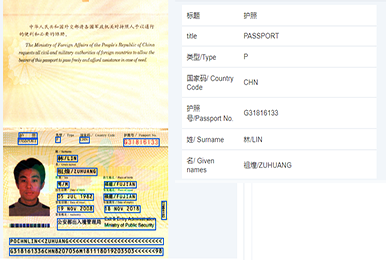
计算机视觉识别技术在金融领域的应用旨在提高金融业务的效率和安全性,同时满足日益增长的客户需求和市场变化。通过身份认证和反欺诈技术,可以自动识别和验证客户的身份,预防欺诈行为;通过自动风险评估和管理,可以自动评估信用风险并制定相应的授信策略;通过金融监管和合规技术,可以自动检测和分析金融机构的运营数据,确保其符合相关法规要求;通过投资策略优化技术,可以自动识别出潜在的投资机会和风险,帮助投资者制定更加科学和有效的投资策略;通过智能客户服务技术,可以自动识别客户的问题和反馈,提供更加个性化和高效的服务。计算机视觉技术的广泛应用将为金融行业带来新的发展机遇和挑战。
-
能源
大型语言模型在金融领域具有多样化和高度价值的应用潜力,涵盖量化交易、风险评估、客户服务、合规监管到市场分析等多个方面。这些模型可以通过深度分析金融数据、市场新闻和社交媒体等非结构化信息,为投资决策、信贷审批和市场洞察提供更高级别的自动化和精准性。然而,应用这些先进技术也带来了一系列复杂和敏感的挑战,其中包括对高度敏感的金融数据进行安全和隐私保护,确保模型输出的准确性和可靠性,以及满足金融监管的严格要求。这不仅需要金融机构本身具备高度的技术和伦理责任观念,还需要与技术供应商、监管机构和其他利益相关方进行广泛而深入的合作和沟通。简而言之,大型语言模型为金融行业带来了前所未有的机会和便利,但这些优势并不能轻易地与安全性、合规性和伦理责任相兼容,需要各方共同努力和谨慎操作。
-
交通物流
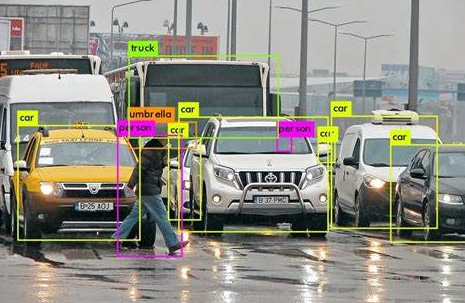
大型语言模型在交通和物流领域有广泛的应用前景,从路径优化、调度决策,到客户服务和数据分析等都显示出巨大的潜力。这些模型能够处理大量非结构化数据,提供准确的预测和深刻的市场洞见,从而提高整个物流和交通系统的效率和客户满意度。然而,与此同时也面临数据安全、准确性和合规性等多方面的挑战。特别是在涉及敏感信息和关键决策时,如何确保模型的可靠性和安全性成为一大关注焦点。因此,在推广应用的过程中需要综合考虑这些因素,确保技术创新与伦理、安全和合规性相结合。
-
医疗健康
大型语言模型在医疗健康领域展现出巨大的应用潜力,包括支持诊断决策、辅助药物研发、提升患者互动和教育,以及自动化医疗文档处理等多个方面。这些模型能够快速和精准地分析大量复杂的医学数据和文献,以便为医生、研究人员和患者提供更准确、更个性化的服务。然而,这一切都伴随着数据隐私、准确性和医疗伦理等重要挑战。尤其在涉及高度敏感和复杂的医疗信息时,如何确保数据的安全性和模型的可靠性是至关重要的。因此,大型语言模型的医疗应用不仅需要技术创新,还必须在法律和伦理层面得到严格的审查和规范,以确保其安全、有效并符合合规要求。
-
制造
大型语言模型在制造业中具有多维度的应用价值,从生产流程优化、质量控制,到供应链管理和员工培训都有其独到之处。模型可以通过分析大量生产数据和市场信息,提供更加精准和高效的决策支持,从而助力提升产品质量、降低成本和提高市场竞争力。同时,它还能辅助生成培训材料和实时技术支持,进一步增强制造业的人力资源质量。然而,这些应用也带来了数据安全、准确性和合规性等一系列挑战。敏感或专有的生产数据需要严格的安全保障,而模型在生产决策中的误判可能会导致严重的经济损失或安全风险。因此,要在制造业中成功应用大型语言模型,就必须综合考虑这些因素,确保其应用既创新又安全,同时也符合行业和法律规定。
-
农业及环保
大型语言模型在农业和环保领域有广泛应用潜力,从作物预测、自然资源保护到废物管理与环境监测,其能通过数据分析提供决策支持和优化方案。这不仅能提升农业生产效率,还有助于更有效地保护环境和自然资源。然而,这些应用也伴随多重挑战,包括数据准确性、可持续性、法律合规性等问题。因此,在推动其在这两个领域的应用时,需要综合考虑各种因素,确保其不仅能带来经济效益,同时也是环境友好和社会责任的。
-
工业互联网
大型语言模型在工业互联网中有着重要的应用价值,从预测性维护、生产优化到供应链管理和质量控制,其都能通过数据分析来提供准确和及时的决策支持。这不仅可以显著提高生产效率,还能有效降低运营成本和风险。然而,这也带来了数据安全、准确性和合规性等方面的挑战。特别是工业数据通常具有很高的敏感性和复杂性,这就需要确保模型在应用过程中的数据安全和准确性。同时,模型的集成和兼容性也是实现其在工业互联网中成功应用的关键因素。因此,在推动大型语言模型在工业互联网中的应用时,需要全面考虑这些问题,以确保其既实用又可靠。
-
电信
大型语言模型在电信行业具有广泛而深刻的应用潜力,包括但不限于客户服务自动化、网络性能优化、欺诈检测、市场分析和实时监控。通过智能地分析大量用户数据和网络指标,这些模型能够自动优化网络配置、识别潜在的安全风险、并提供针对性的市场和客户策略。尤其在提升客户体验、降低运营成本和提高网络稳定性方面,其表现出强大的价值。然而,随着应用的广泛化,也出现了一系列挑战,其中包括如何确保用户数据的安全和隐私,如何保证服务的准确性和响应速度,以及如何满足不断变化的法律和合规要求。总体而言,大型语言模型为电信行业带来了革命性的变革和无限的可能,但在实际应用中,也需要充分考虑到各种风险和挑战,以确保其可持续、安全和合规地运行。
-
教育
大型语言模型在教育领域表现出巨大的应用潜力和价值,包括个性化学习、自动评估、课程推荐以及教育数据分析等方面。这些模型能够针对个体学生的需求提供个性化的教育资源和反馈,同时也能辅助教师和教育机构进行更为精准的教学设计和政策制定。然而,应用中也需要谨慎处理数据隐私、教育公平性和法律合规等问题。综合而言,大型语言模型为教育现代化和个性化提供了有力的工具和机会,但在推广应用时必须全面考虑其复杂性和多维度的挑战。
-
电商
大型语言模型在电商行业中具有多方面的应用和重大的影响。从推荐系统的个性化匹配、客户服务的自动化响应,到销售预测和价格优化,这些模型都能够实现高度精准和自动化的商业决策,从而大幅提升电商平台的运营效率和客户满意度。特别是在数据驱动的电商环境中,模型能够深入挖掘和分析庞大的用户数据,提供更为精细化的营销策略和客户体验优化。此外,模型还能自动生成各种营销和产品内容,进一步降低人力成本和提高运营效率。然而,应用这些模型也存在一系列挑战和风险,包括但不限于用户数据的隐私和安全保护,模型推荐和预测的准确性和可靠性,以及合规性和道德考虑,例如避免使用误导性或不当的营销手段。因此,在全面推广大型语言模型于电商应用之前,必须仔细考量这些复杂因素,并采取相应的风险控制和合规性保障措施。
-
游戏
大型语言模型在游戏产业中的应用已经展示出多元化和深远的影响,从改进游戏设计、增强角色互动,到优化玩家体验和提供高效的客服支持,这些模型在方方面面都有着不可忽视的作用。特别是在剧情生成、NPC(非玩家角色)的自然对话设计、以及玩家行为分析上,大型语言模型能够提供更为深入和个性化的游戏体验。通过数据分析和模式识别,这些模型也能够帮助游戏开发者更准确地预测和满足玩家的需求,从而在激烈的市场竞争中获得优势。然而,模型应用也面临诸多挑战,包括数据安全和隐私问题、保证用户体验的均衡性、以及快速而准确的响应能力。此外,合规性和道德考量也是不能忽视的方面,比如需要遵循与儿童安全和数据保护相关的法律规定。但在实际应用中,也需要全面和审慎地考虑到其伴随而来的风险和挑战,以确保模型的应用既高效又负责任。这样的全面性考虑和应用将有助于模型在游戏产业中的持续和健康发展,推动这一产业进入更加智能化和个性化的新时代。
 样本数据预处理
样本数据预处理 模型训练
模型训练 模型应用
模型应用 持续优化
持续优化